摘要
KNN(K Nearest Neighbor)算法是采用测量不同特征值之间的距离方法进行分类,也就是说对于每个样本数据,需要和训练集中的所有数据进行欧氏距离计算。KNN算法也是机器学习(Machine Learning)的最基础算法之一。
在这次课程设计中,实现使用KNN算法实现识别转换为txt格式的二值化数字。
关键字 :KNN, Machine Learning, Python, 二值化数字识别
1. 简述KNN算法 1.1 什么是K Nearest Neighbor? KNN 是通过测量不同特征值之间的距离进行分类的方法。
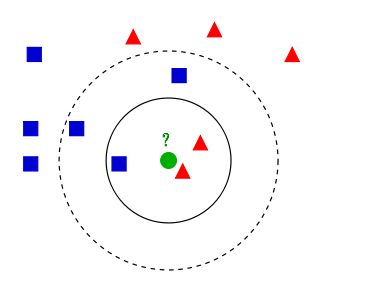
K近邻算法,即是给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的K个实例,这K个实例的多数属于某个类,就把该输入实例分类到这个类中。(这就类似于现实生活中少数服从多数的思想)以引自维基百科上的一幅图为例:
如上图所示,有两类不同的样本数据,分别用蓝色的小正方形和红色的小三角形表示,而图正中间的那个绿色的圆所标示的数据则是待分类的数据。这也就是我们的目的,来了一个新的数据点,我要得到它的类别是什么?好的,下面我们根据k近邻的思想来给绿色圆点进行分类:
如果K=3,绿色圆点的最邻近的3个点是2个红色小三角形和1个蓝色小正方形,少数从属于多数,基于统计的方法,判定绿色的这个待分类点属于红色的三角形一类。
如果K=5,绿色圆点的最邻近的5个邻居是2个红色三角形和3个蓝色的正方形,还是少数从属于多数,基于统计的方法,判定绿色的这个待分类点属于蓝色的正方形一类。
1.2 怎么度量“最邻近距离”? 在1.1中说到,k近邻算法是在训练数据集中找到与该实例最邻近的K个实例,这K个实例的多数属于某个类,那么判断预测点属于那个类。
定义中所说的最邻近是如何度量呢?我们怎么知道谁跟测试点最邻近。这里就会引出我们几种度量俩个点之间距离的标准:
设特征空间$X$是n维实数向量空间$R^{n}$, $x_i.x_j\in X$, $x_i = (x_i^{(1)},x_i^{(2)},\cdots,x_i^{(n)})^T$, $x_j = (x_j^{(1)},x_j^{(2)},\cdots,x_j^{(n)})^T$, $x_i,x_j$的$L_p$的距离定义为:
这里$p\geq 1$. 当$p=2$时,称为欧式距离(Euclidean Distance),即:
当$p=1$时,称为曼哈顿距离(Manhattan Distance),即:
当$p=\infty$时,它是各个坐标距离的最大值,即:
其中当p=2的时候,就是我们最常见的欧式距离,我们也一般都用欧式距离来衡量我们高维空间中俩点的距离。在实际应用中,距离函数的选择应该根据数据的特性和分析的需要而定,一般选取p=2欧式距离表示,这不是本文的重点。
2. 使用KNN算法识别二值化数字 2.1 算法实现步骤
待处理数据准备
将32*32的二进制图像矩阵转换为1*1024的向量
下面是32*32的黑白图像:
为了方便处理,根据灰度处理成二进制文本文件(可从图上看出是数字2):
代码:
1 2 3 4 5 6 7 8 9 def img2vector (filename ): returnVect = zeros((1 ,1024 )) fr = open(filename) for i in range(32 ): linestr = fr.readline() for j in range(32 ): returnVect[0 ,32 *i+j] = int(linestr[j]) return returnVect
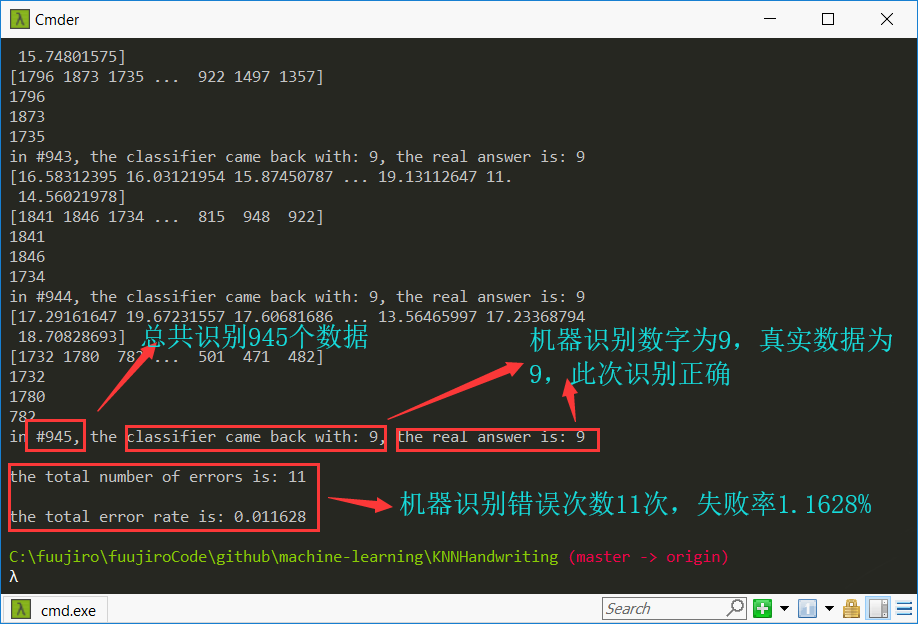
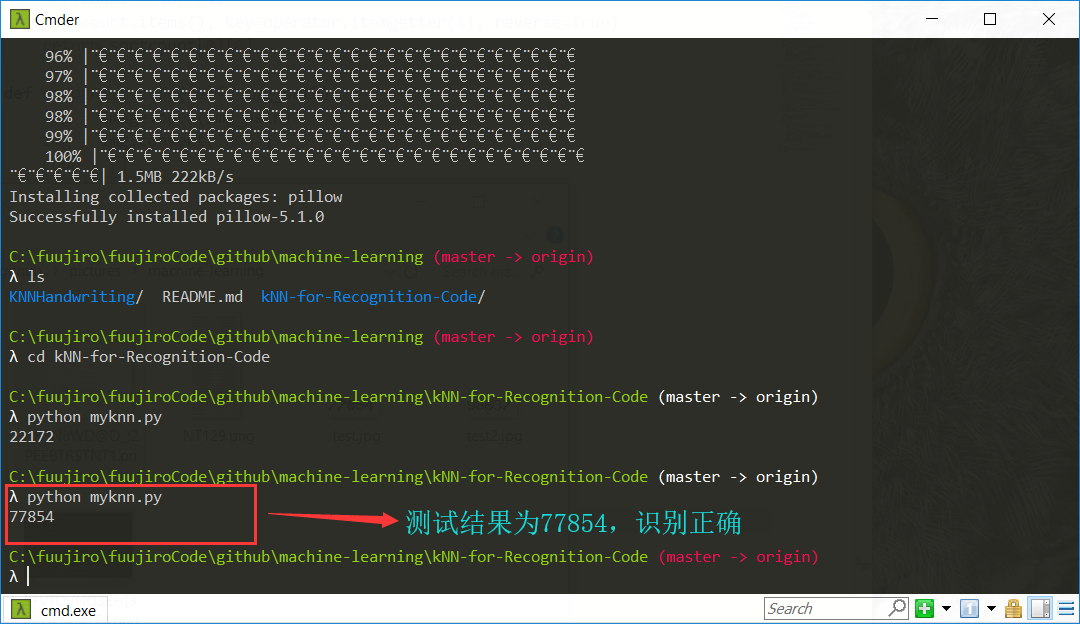
运行程序,统计识别结果
2.2 源代码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 def img2vector (filename ): '图像文件转换成矩阵' returnVect = zeros((1 ,1024 )) fr = open(filename) for i in range(32 ): lineStr = fr.readline() for j in range(32 ): returnVect[0 ,32 *i+j] = int(lineStr[j]) return returnVect def handwritingClassTest (): '手写识别测试函数,调用了KNN模块的KNN分类器函数' hwLabels = [] trainingFileList = listdir('trainingDigits' ) m = len(trainingFileList) trainingMat = zeros((m,1024 )) for i in range(m): fileNameStr = trainingFileList[i] fileStr = fileNameStr.split('.' )[0 ] classNumStr = int(fileStr.split('_' )[0 ]) hwLabels.append(classNumStr) trainingMat[i,:] = img2vector('trainingDigits/%s' % fileNameStr) testFileList = listdir('testDigits' ) errorCount = 0.0 mTest = len(testFileList) for i in range(mTest): fileNameStr = testFileList[i] fileStr = fileNameStr.split('.' )[0 ] classNumStr = int(fileStr.split('_' )[0 ]) vectorUnderTest = img2vector('testDigits/%s' % fileNameStr) classifierResult = KNN.classify0(vectorUnderTest, trainingMat, hwLabels, 3 ) print "in #%d, the classifier came back with: %d, the real answer is: %d" % (i, classifierResult, classNumStr) if (classifierResult != classNumStr): errorCount += 1.0 print "\nthe total number of errors is: %d" % errorCount print "\nthe total error rate is: %f" % (errorCount/float(mTest)) handwritingClassTest()
3. 使用KNN算法识别验证码 各大门户网站为防止DDos恶意攻击都设置验证码。然而验证码的存在,无疑让我们作为用户快速认证的想法破灭了,但是No big problem,用KNN算法就能实现识别验证码,再写个脚本,以后的所有验证码就可以自动输入。
验证码是这样的:
其实就是简单地把字符进行旋转然后加上一些微弱的噪点形成的。反向思考,首先二值化去掉噪点,然后把单个字符分割出来,最后旋转至标准方向,然后从这些处理好的图片中选出模板,最后每次新来一张验证码就按相同方式处理,然后和这些模板进行比较,选择判别距离最近的一个模板作为其判断结果(亦即KNN的思想)。
3.1 获取验证码 通过爬虫爬取大量验证码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 import urllib,urllib2,cookielib,string,Imagedef getchk (number ): cookie = cookielib.LWPCookieJar() cookieSupport= urllib2.HTTPCookieProcessor(cookie) opener = urllib2.build_opener(cookieSupport, urllib2.HTTPHandler) urllib2.install_opener(opener) headers = { 'Accept' :'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8' , 'Accept-Encoding' :'gzip,deflate' , 'Accept-Language' :'zh-CN,zh;q=0.8' , 'User-Agent' :'Mozilla/5.0 (Windows NT 6.2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.111 Safari/537.36' } req0 = urllib2.Request( url ='http://mis.teach.ustc.edu.cn' , headers = headers ) try : result0 = urllib2.urlopen(req0) except urllib2.HTTPError,e: print e.code getcookie = ['' ,] for item in cookie: getcookie.append(item.name) getcookie.append("=" ) getcookie.append(item.value) getcookie = "" .join(getcookie) headers["Origin" ] = "http://mis.teach.ustc.edu.cn" headers["Referer" ] = "http://mis.teach.ustc.edu.cn/userinit.do" headers["Content-Type" ] = "application/x-www-form-urlencoded" headers["Cookie" ] = getcookie for i in range(number): req = urllib2.Request( url ="http://mis.teach.ustc.edu.cn/randomImage.do?date='1469451446894'" , headers = headers ) response = urllib2.urlopen(req) status = response.getcode() picData = response.read() if status == 200 : localPic = open("./source/" +str(i)+".jpg" , "wb" ) localPic.write(picData) localPic.close() else : print "failed to get Check Code " if __name__ == '__main__' : getchk(500 )
获得到足够多的验证码后(大约100张)即可。
3.2 二值化 我们可以使用matlab来进行二值化处理,图像处理函数能省下很多时间,遍历验证码所储存文件夹,对每一张验证码图片进行二值化处理,把处理过的图片存入新建文件夹下。代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 mydir='./source/' ; bw = './outcome/' ; if mydir(end)~='\' mydir=[mydir,' \']; end DIRS=dir([mydir,' *.jpg']); %扩展名 n=length(DIRS); for i=1:n if ~DIRS(i).isdir img = imread(strcat(mydir,DIRS(i).name )); img = rgb2gray(img);%灰度化 img = im2bw(img);%0-1二值化 name = strcat(bw,DIRS(i).name) imwrite(img,name); end end
处理后:
3.3 分割 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 mydir='./outcome/' ; letter = './letter/' ; if mydir(end)~='\' mydir=[mydir,' \']; end DIRS=dir([mydir,' *.jpg']); %扩展名 n=length(DIRS); for i=1:n if ~DIRS(i).isdir img = imread(strcat(mydir,DIRS(i).name )); img = im2bw(img);%二值化 img = 1-img;%颜色反转让字符成为联通域,方便去除噪点 for ii = 0:3 region = [ii*20+1,1,19,20];%把一张验证码分成四个20*20大小的字符图片 subimg = imcrop(img,region); imlabel = bwlabel(subimg); % imshow(imlabel); if max(max(imlabel))>1 % 说明有噪点,要去除 % max(max(imlabel)) % imshow(subimg); stats = regionprops(imlabel,' Area'); area = cat(1,stats.Area); maxindex = find(area == max(area)); area(maxindex) = 0; secondindex = find(area == max(area)); imindex = ismember(imlabel,secondindex); subimg(imindex==1)=0;%去掉第二大连通域,噪点不可能比字符大,所以第二大的就是噪点 end name = strcat(letter,DIRS(i).name(1:length(DIRS(i).name)-4),' _',num2str(ii),' .jpg') imwrite(subimg,name); end end end
处理后:
3.4 旋转 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 if mydir(end)~='\' mydir=[mydir,' \']; end DIRS=dir([mydir,' *.jpg']); %扩展名 n=length(DIRS); for i=1:n if ~DIRS(i).isdir img = imread(strcat(mydir,DIRS(i).name )); img = im2bw(img); minwidth = 20; for angle = -60:60 imgr=imrotate(img,angle,' bilinear',' crop');%crop 避免图像大小变化 imlabel = bwlabel(imgr); stats = regionprops(imlabel,' Area'); area = cat(1,stats.Area); maxindex = find(area == max(area)); imindex = ismember(imlabel,maxindex);%最大连通域为1 [y,x] = find(imindex==1); width = max(x)-min(x)+1; if width<minwidth minwidth = width; imgrr = imgr; end end name = strcat(rotate,DIRS(i).name) imwrite(imgrr,name); end end
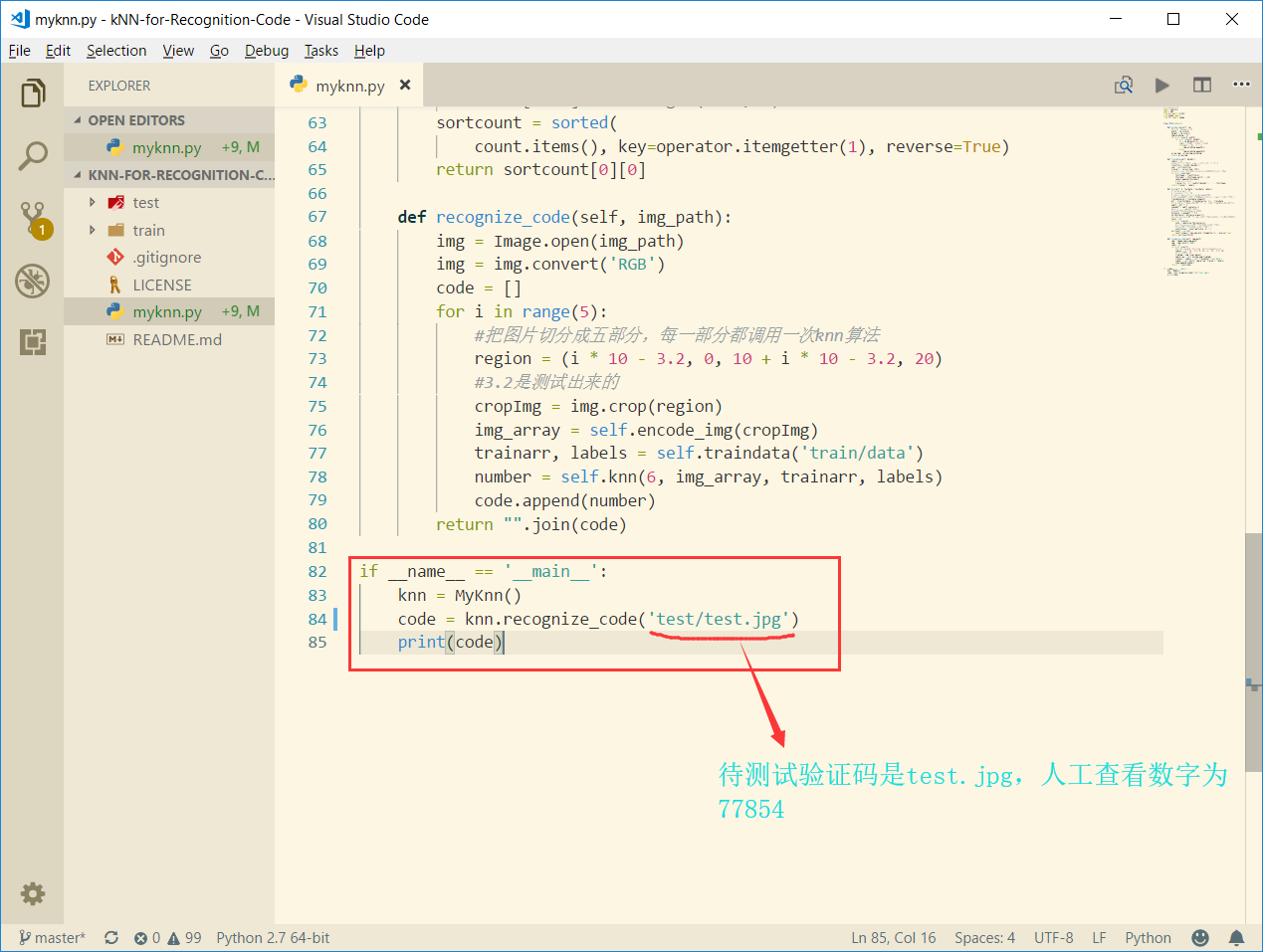
3.5 运行处理代码,统计识别结果
结果 :验证码识别正确。
3.6 源代码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 class MyKnn (object ): def encode_img (self, im ): width = im.size[0 ] height = im.size[1 ] img_encoding = [] for i in range(0 , width): for j in range(0 , height): cl = im.getpixel((i, j)) clall = cl[0 ] + cl[1 ] + cl[2 ] if (clall == 0 ): img_encoding.append(1 ) else : img_encoding.append(0 ) array_img = array(img_encoding) return array_img def traindata (self, datadir ): labels = [] trainfile = listdir(datadir) num = len(trainfile) trainarr = zeros((num, 200 )) for i in range(num): thisfname = trainfile[i] thislabel = thisfname.split('_' )[0 ] labels.append(thislabel) trainarr[i, :] = loadtxt(datadir + '/' + thisfname) return trainarr, labels def knn (self, k, testdata, traindata, labels ): traindatasize = traindata.shape[0 ] dif = tile(testdata, (traindatasize, 1 )) - traindata sqdif = dif ** 2 sumsqdif = sqdif.sum(axis=1 ) distance = sumsqdif ** 0.5 sortdistance = distance.argsort() count = {} for i in range(k): vote = labels[sortdistance[i]] count[vote] = count.get(vote, 0 ) + 1 sortcount = sorted( count.items(), key=operator.itemgetter(1 ), reverse=True ) return sortcount[0 ][0 ] def recognize_code (self, img_path ): img = Image.open(img_path) img = img.convert('RGB' ) code = [] for i in range(5 ): region = (i * 10 - 3.2 , 0 , 10 + i * 10 - 3.2 , 20 ) cropImg = img.crop(region) img_array = self.encode_img(cropImg) trainarr, labels = self.traindata('train/data' ) number = self.knn(6 , img_array, trainarr, labels) code.append(number) return "" .join(code) if __name__ == '__main__' : knn = MyKnn() code = knn.recognize_code('test/test.jpg' ) print(code)
4. 课程设计总结 在大二的尾声里,我也即将写完第4个学期的软件实践班的课程大作业,回望过去的两年,我在计算机科学的海洋里像一块海绵一样,疯狂地汲取了水分,增长了知识和见解,提高了自己的编程能力。我发现我知道的东西越多,自己的知识面就越来越小,我认为和登山站高望远的道理一样,计算机科学是值得这一辈子好好钻研的,希望自己在剩下的本科的两年,踏踏实实地好好学下去。比如在机器学习地方向,抑或是我更感兴趣的计算机架构方向上,加油!
附录:
以上所有代码可在 https://github.com/fuujiro/machine-learning 上下载。
文章同步发布在我的Blog:https://blog.fuujiro.com