





关于“中美互加关税事件”的可视化文本分析
摘要
中美贸易战在2018年3月开始愈演愈烈,从4月开始美方开始对价值约500亿美元的商品加征关税,不久中方也以其人之道还至其身,同样加征关税,中美互加关税这一事件在微博上引起热烈讨论…
借着课程设计的机会,准备分析一下关于“中美互加关税”这一事件,网友们的网上言论随时间变化的趋势。于是,使用爬虫爬取了微博网友的评论数据,用Python和Matlab进行文本分析和可视化数据分析。
关键字:Python, 结巴中文分词, 文本可视化
环境:Python2.7, MongoDB 3.2.0, jieba
1. 获取微博数据
1.1 使用SinaSpider
SinaSpider-基于scrapy和redis的分布式微博爬虫。SinaSpider主要爬取新浪微博的个人信息、微博数据、关注和粉丝。数据库设置 Information、Tweets、Follows、Fans四张表。爬虫框架使用Scrapy,使用scrapy_redis和Redis实现分布 式。此项目实现将单机的新浪微博爬虫重构成分布式爬虫。
sina_reptile- 这是一个关于sina微博的爬虫,采用python开发,并修改了其sdk中的bug,采用mongodb存储,实现了多进程爬取任务。 获取新浪微博1000w用户的基本信息和每个爬取用户最近发表的50条微博,使用python编写,多进程爬取,将数据存储在了mongodb中
sina_weibo_crawler- 基于urlib2及beautifulSoup实现的微博爬虫系统。利用urllib2加beautifulsoup爬取新浪微博,数据库采用mongodb,原始关系以txt文件存储,原始内容以csv形式存储,后期直接插入mongodb数据库
sina-weibo-crawler-方便扩展的新浪微博爬虫。WCrawler.crawl()函数只需要一个url参数,返回的用户粉丝、关注里面都有url,可以向外扩展爬取,并且也可以自定义一些过滤规则。
weibo_crawler-基于Python、BeautifulSoup、mysql微博搜索结果爬取工具。本工具使用模拟登录来实现微博搜索结果的爬取。
SinaMicroblog_Creeper-Spider_VerificationCode- 新浪微博爬虫,获得每个用户和关注的,粉丝的用户id存入xml文件中,BFS,可以模拟登陆,模拟登陆中的验证码会抓取下来让用户输入。
1.2 使用知微平台
当然也可以直接使用知微平台爬取的数据
2. 文本分析
2.1 词频分析
我们可以统计一下次数最多的30个词。
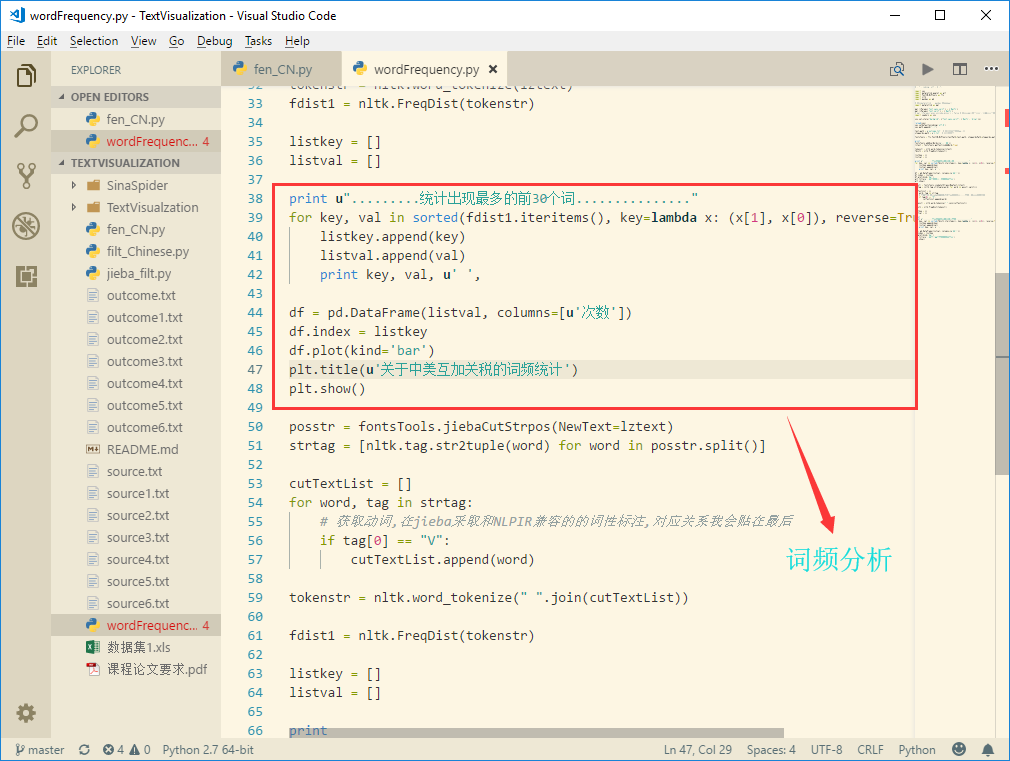
代码展示1
2
3
4
5
6
7
8
9
10
11
12
13
14print u".........统计出现最多的前30个词..............."
for key, val in sorted(fdist1.iteritems(), key=lambda x: (x[1], x[0]), reverse=True)[:30]:
listkey.append(key)
listval.append(val)
print key, val, u' ',
df = pd.DataFrame(listval, columns=[u'次数'])
df.index = listkey
df.plot(kind='bar')
plt.title(u'关于中美互加关税的词频统计')
plt.show()
posstr = fontsTools.jiebaCutStrpos(NewText=lztext)
strtag = [nltk.tag.str2tuple(word) for word in posstr.split()]
2.2 筛选中文字段
首先查阅ASCII码,了解到中文所有字符的ASCII码值区间为[\u4e00-\u9fa5]
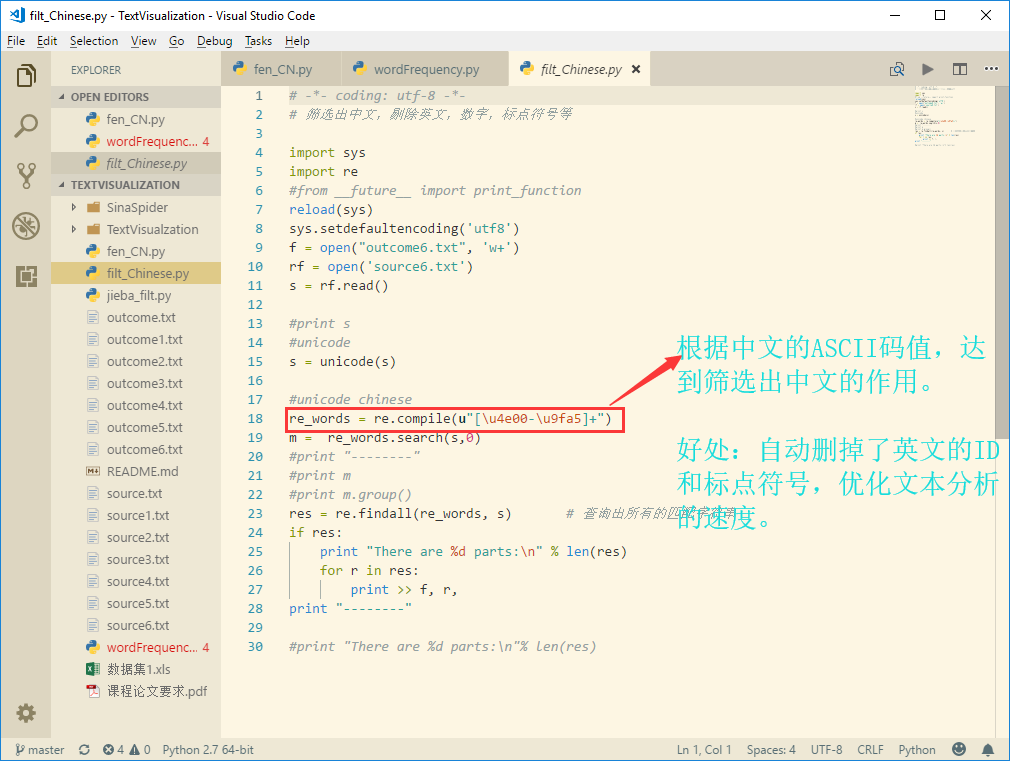
未经处理的原文字:
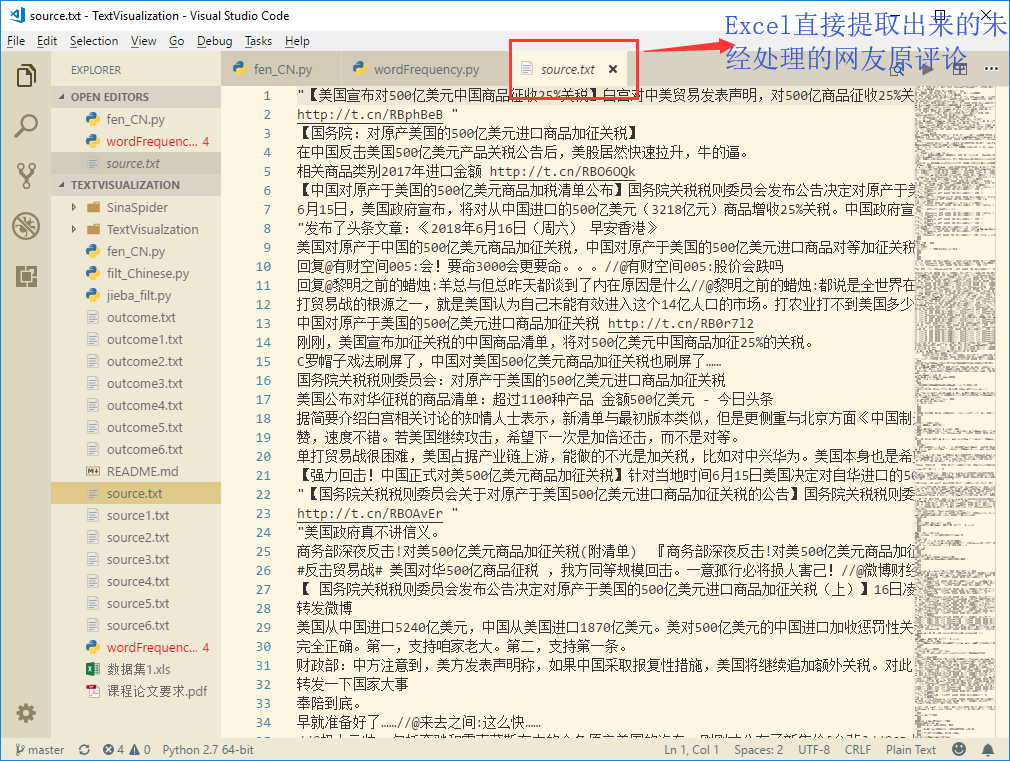
处理后的文字:
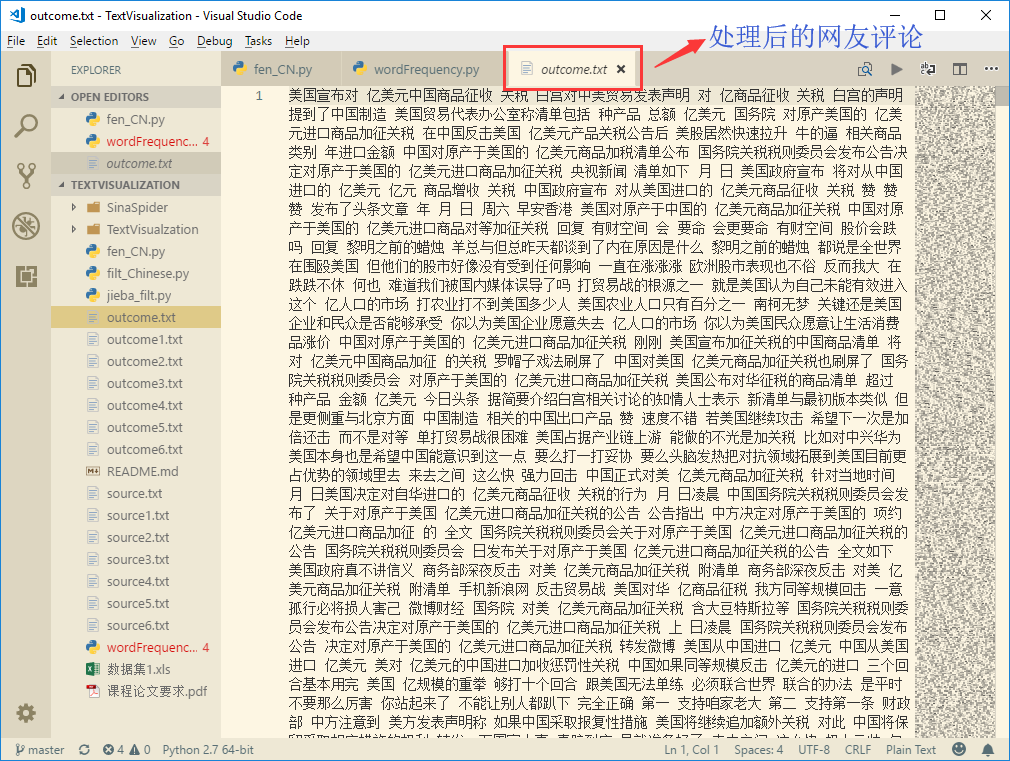
结论:可以直观地相比起原文字,经过处理后,筛除了所有英文字母和标点符号,只留下了文本分析需要的中文字段。
2.3 结巴中文分词
jieba分词:结巴中文分词是著名开源代码托管平台GitHub的Python中文分词组件
特点:
支持三种分词模式:
- 精确模式,试图将句子最精确地切开,适合文本分析;
- 全模式,把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义;
- 搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
支持繁体分词
支持自定义词典
使用步骤:
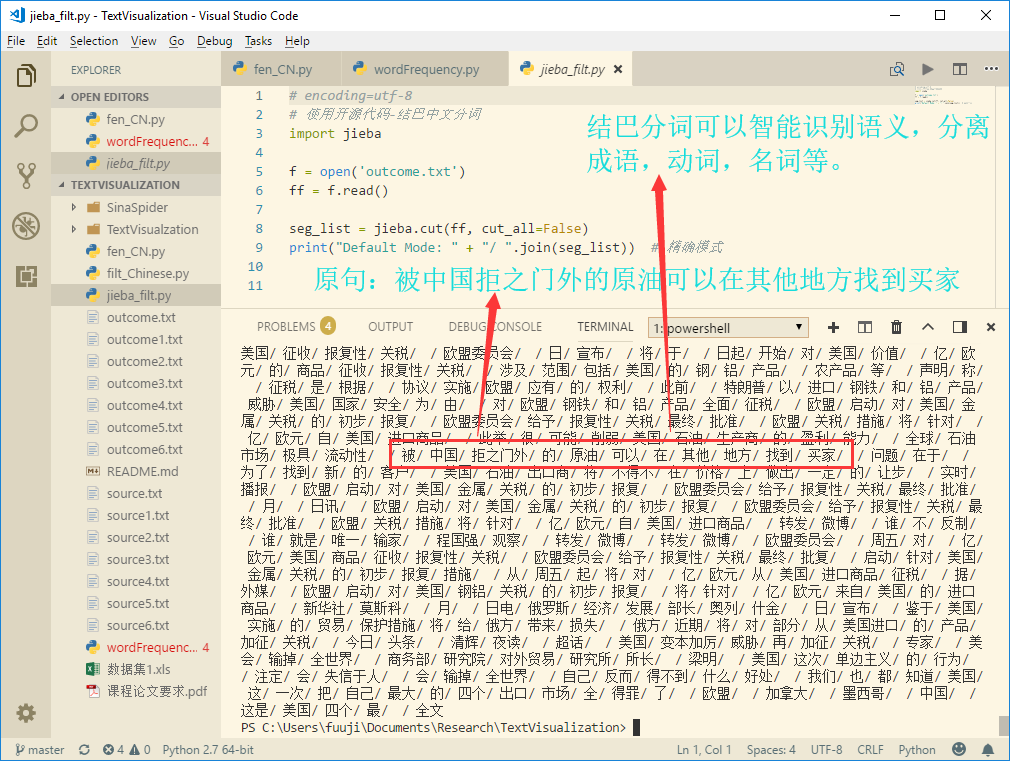
结论:结巴中文分词可以智能地根据语义,拆分语句,断成一个个有血有肉,独立意义的词语,有利于后期词云制作时的关键词筛选。
3. 可视化分析-词云制作
3.1 使用Python库实现词云
环境:matplotlib, jieba, wordcloud
代码实现:
1 |
|
但是,这样做出来的词云很难看,实在是无法忍受。
3.2 使用Wordart制作词云
使用Wordart工具,极富艺术感和高度定制化的词云制作工作,进行词云制作和可视化分析。
那么问题来了,我们如何进行进行数据随时间变化的趋势的可视化分析呢?
首先使用Excel分析微博数据的发布时间,发现时间从6.15到6.20的6天一共2448条数据,我们拆分成6个小数据集进行上面的第2个步骤,进行6次分析。
6月15日的可视化词云

- 6月16日的可视化词云

- 6月17日的可视化词云

- 6月18日的可视化词云

- 6月19日的可视化词云

- 6月20日的可视化词云

- 6月15日到6月20日总数据的可视化词云

结论:可以看出网友们评论,核心词一直围绕关税,让人眼前一亮的是汽车似乎也是百姓们关注的热点,这说明我国平民百姓热衷于购买外国进口汽车,我国汽车产业也依赖于美国,政府应该重视这一问题,拉动国内汽车产业迎头追赶,蓬勃发展。关于高频词随时间变化,我们可以看出:
- 15号是
关税,汽车,项约等:汽车是网友们关注的热点。 - 16号是
汽车,华为,农产品等:农产品出口,进口汽车,华为海外受挫开始被网友们议论。 - 17号是
制裁,罚款,中兴等:美国政府对中兴的高额罚款和制裁措施,引起网友热议。 - 18号是
罚款,中兴制裁,强硬反击,以战止战等:网友们爱国民族情绪高涨,主张贸易战抗衡。 - 19号是
贸易战,物价,特朗普等:特朗普政府的对华贸易政策引起热议。 - 20号是
特朗普,老百姓,贸易战:贸易战和特朗普仍然是关键热词。
附录
- Wikipedia-2018 China–United States trade war
- 结巴中文分词
- Wordart
- 爬取的原数据,处理后的数据和源代码都在附件压缩包中